
As organizations build increasingly complex AI ecosystems, agentic architectures have emerged as a powerful approach. These systems involve multiple autonomous agents interacting to plan, delegate, and execute tasks. This interaction between agents is called agent-to-agent (A2A) communication. The Model Context Protocol (MCP) is an emerging convention for structuring how language models call tools, APIs, and other agents by encoding instructions and definitions directly into their context window. It is gaining traction as a way to structure those interactions, allowing models to invoke tools, APIs, and other agents through well-defined context formats. However, this convenience comes with significant security implications similar to those we experience from service-oriented architecture (SOA).
Before enabling communication between agents, the session itself must be secure. With MCP, we must treat the agent as an untrusted actor. One capable of interpreting but not enforcing protocol structure. Here we’ll attempt to outline the practical steps necessary to secure A2A communication in AI systems, particularly those using or considering MCP. While MCP enables flexible orchestration of AI behaviors, it also introduces a new, subtle attack surface that must be actively managed if it is to be used.
")
MCP Is Just Text. Treat It Like a Threat
MCP standardizes how tools and model behaviors are described and invoked within the AI’s context window. This structure exists purely as text. It is not enforced by the model or runtime. Treat MCP as a convenience layer for instruction, not a security boundary.
- The model interprets the MCP structure; it is not hard-coded.
- Prompt injection, context manipulation, and tool misuse remain high-probability risks. Prompt injection can manipulate or override tool descriptions.
- Context stuffing (exceeding token limits) can silently push MCP metadata out of view.
- MCP can be escaped or redefined by malicious or malformed prompts.
- Tool redescription attacks allow an adversary to reframe what a tool does by rewriting its name or purpose in context.
Hint: Even when MCP is well-formed, the LLM remains an untrusted participant. Execution boundaries must be enforced at the infrastructure level, not inside the prompt.
What is the Model’s Context Window?
The context window is the model’s working memory; the full set of text it uses to generate a response. This includes system instructions, user prompts, prior interactions, and any structured elements (like MCP definitions or tool specs).
Unlike traditional software, the model doesn’t enforce rules. It reads structure as text, not code. If the MCP protocol is unclear, incomplete, or overwritten, the model may misinterpret it or ignore it entirely.
That’s why MCP must be treated as advisory, not authoritative, and why the model itself should be considered an untrusted interpreter, not a secure protocol agent.
Guardrails Enforce Execution Boundaries Outside the Model
Even when tool definitions and workflows are structured through MCP, they must be treated as recommendations, not commands. The actual execution of any action (tool, API call, function) should be governed by infrastructure-level controls that sit outside the model’s context window.
Here are five mechanisms organizations can use to enforce real boundaries:
1 Use a Policy-Aware Execution Gateway
Route all tool invocations through a broker service or gateway that inspects and approves requests before they’re passed to the actual tool or function (e.g., using a gateway like Gloo AI Gateway, deployed downstream of MCP). A policy-aware execution gateway helps unify access to multiple LLM providers behind a single secured interface. By placing this control at the proxy layer, we gain the ability to apply traffic shaping, authorization, rate limiting, and audit policies to every model-generated request. This central point of enforcement allows accelerated development while maintaining control over security and compliance. See the appendix for a basic illustration of the architecture.
This gateway service broker should:
- Validate that the tool being called is on an allowlist
- Check arguments against policy constraints (e.g., allowed directories, safe operations, data loss prevention)
- Apply identity or session-based access rules
- Return structure errors when violations occur
This isolates the model from direct access to system capabilities and creates an interception point for oversight. A well-designed gateway should also perform Data Loss Prevention (DLP). This means scanning outbound tool calls for sensitive data such as credentials, PII (Personally Identifiable Information), or classified internal documents, before execution. Integrating DLP into the gateway ensures content-level safety and prevents agents from unintentionally exfiltrating protected information.
2. Implement Signature Verification for Tool Definitions
Each MCP-defined tool or plugin should be cryptographically signed and verified at runtime. This ensures:
- The tool definition wasn’t tampered with in the prompt context.
- Only registered, trusted tools can be called
- Version control over function behavior
Think of this like signing a container image or binary. It’s proof of origin and intent.
3. Introduce Human-in-the-Loop or Policy Escalation Paths
Not all tool calls should be executed automatically. For sensitive actions (deleting data, modifying permissions, triggering transactions):
- Require human review and approval
- Or enforce dynamic runtime checks using a policy engine integrated with the policy-aware execution gateway (e.g., Open Policy Agent, Cedar)
Use “break-glass” logic: automate the common, alert or escalate the risky.
4. Sandbox Tool Execution
Every model-initiated action should occur inside a hardened execution environment with clear limits:
- File access scoped to ephemeral directories
- No open network calls unless explicitly permitted
- Resource usage (CPU, memory) capped per invocation
- Write-once or audit-only file systems, where applicable
This limits the blast radius and prevents lateral movement if something goes wrong.
5. Monitor and Audit Model Behavior Like a Production System
Leveraging the logging from the policy-aware execution gateway (see appendix), capture telemetry on every tool call, including:
- Invocation time and parameters
- The context (what led the model to make this call)
- The result, side effects, and downstream impact
Feed this into observability pipelines. In this setup, the model becomes a dynamic, partially autonomous user in your system. What you can’t log, you can’t secure.

Trust Nothing, Log Everything, Watch the Prompt Like a Perimeter
Your prompt is your new attack surface.
The structure, metadata, and tool definitions you embed in the prompt are vulnerable:
- They can be injected into
- They can be truncated
- They can be reinterpreted or overwritten by other agents, plugins, or the model itself
Treat every tool like it may be called wrong
Even well-formed tool definitions can be misused. An exposed delete_user() function needs constraints:
- Input validation: enforce types, required fields, and expected ranges
- Context-aware defaults: avoid doing anything destructive without clear intent
- Separate registries: don’t mix public and admin tools in the same space
Observe everything
This logging must happen outside the model, at the Policy-Aware Execution Gateway, not within the MCP layer. The MCP Gateway provides structure, but enforcement and full observability occur at the infrastructure level, where model output becomes executable intent. Log not just the tool calls, but what led to them:
- The prompt content
- Model rationale (if captured)
- Parameters used and their source
- Whether the execution was approved or blocked
Use this observability to:
- Trace incidents and debugging sessions
- Flag unusual patterns or sequences
- Simulate potentially unsafe tool use without impact
Defense in depth still matters
- Require second-agent confirmation for irreversible actions
- Shadow risky tools before exposing them fully
- Never assume that because it worked once, it’s safe to let the model do it again
The prompt is not secure. The model is not trusted. The only thing that keeps you safe is what you do around them.

Adopt Zero-Trust for LLMs and Assume the Model is Confused or Compromised
Never confuse coherent output with safe behavior. Models will:
- Misunderstand poorly described tools
- Fill in gaps with hallucinated assumptions
- Generate malicious sequences under pressure or influence
Build your system as if:
- The model could be tricked
- The prompt could be poisoned
- Every output need verification
MCP gives structure and scale, but you own the consequences.

Conclusion
MCP opens the door to scalable, flexible AI-driven workflows, but it must be approached with caution. Like any protocol that relies on structured suggestions rather than enforcement, MCP increases the complexity and subtlety of your security obligations. A2A systems built with MCP must be supported by rigorous tooling controls, context integrity, and observability. Only then can organizations responsibly harness the power of autonomous AI.
For organizations architecting or assessing agentic AI, MCP should be treated as a new attack surface, not a neutral abstraction. Build as if compromise is inevitable, validate as if the model is malicious, and design with auditability at the core.
Treat every model like an untrusted participant. Handle every tool like a potential exploit. And build infrastructure that can say “no” when it matters.

ABOUT THE RESEARCH
This document was created by a human analyst in collaboration with generative AI. The final content was developed, reviewed, and edited by a human editor to ensure accuracy, originality, and adherence to applicable legal standards.
Appendix A:
Example Architecture
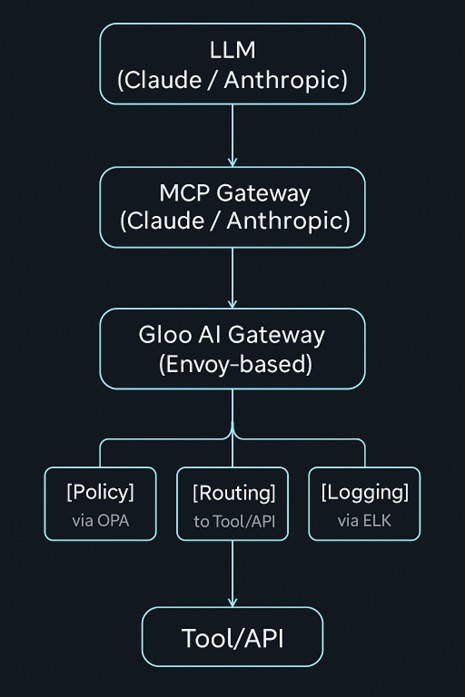
Appendix B: Tools and References
Anthropic. (2024, 4 10). Model Context Protocol (MCP). Retrieved from Anthropic: https://www.anthropic.com/news/model-context-protocol
AWS. (2024, 4 16). Open protocols for agent interoperability, part 1: Inter-agent communication on MCP. Retrieved from AWS Open Source Blog: https://aws.amazon.com/blogs/opensource/open-protocols-for-agent-interoperability-part-1-inter-agent-communication-on-mcp/
Cedar Policy. (n.d.). Cedar: A language for authorization. https://www.cedarpolicy.com/en
Model Context Protocol. (n.d.). MCP servers. Retrieved from GitHub: https://github.com/modelcontextprotocol/servers
Open Policy Agent. (n.d.). OPA: Open Policy Agent. Retrieved from Open Policy Agent: https://www.openpolicyagent.org/
OpenTelemetry Project. (n.d.). OpenTelemetry. Retrieved from OpenTelemetry: https://opentelemetry.io/
Solo.io. (n.d.). Gloo AI Gateway. Retrieved from Solo.io: https://www.solo.io/products/gloo-ai-gateway
Cybersecurity & Risk News, Updates, Resources
HALOCK Breach Bulletin
Exploit Insider
Cybersecurity Awareness Posters